
如何從數據庫挖掘基因并篩選 TagSNP(醫學篇)
在人醫學遺傳學研究中,SNP 與疾病相關性一直是廣泛的研究課題。很多人在剛開始接觸課題,在沒有前期研究基礎指示的目的基因時,都會選擇從公共數據庫中尋找與疾病相關的基因或者SNP進行研究。本文小編帶你學習如何從數據庫中挖掘基因,并聚焦疾病相關的重要通路。
技術路線
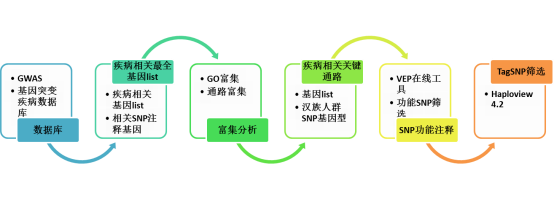
1.疾病/復雜性狀相關數據庫
百度搜索可以獲得很多人疾病相關數據庫的使用說明,在此不再贅述。我們常用的人類疾病數據庫是 DisGeNET(https://www.disgenet.org/search ),常用 GWAS 數據庫是 EMBL-EBI 的 GWAS catalog(https://www.ebi.ac.uk/gwas/ )。
2.疾病相關最全基因 list
通過數據庫下載疾病相關基因列表;相關 SNP 也可以在 VEP 在線注釋工具(http://asia.ensembl.org/Multi/Tools/VEP )注釋其所在的基因。將兩部分基因合并,獲得基本相關較為全面的基因列表。
3.富集分析----聚焦疾病/復雜性狀相關通路
富集分析使用 R 語言的 clusterProfiler 程序包。即使不會 R 語言,不懂編程,一樣可以完成分析。
安裝 R
百度搜索 R,找到合適的下載源;也可直接點擊鏈接https://cran.dcc.uchile.cl/,選擇合適的版本下載。
#設置工作目錄
運行 R 后,在《文件》菜單下選擇《改變工作目錄》;
將基因名替換好以后,直接復制下列代碼到 R,回車運行即可,除此之外可以不做任何改動。如果已經安裝 clusterProfiler 程序包,請從基因編號轉換開始。
#安裝 clusterProfiler 程序包,此種安裝方法適合 R3.5.2 及以下版本,R3.6.0 以上版本請參考文后補充說明。
source("https://bioconductor.org/biocLite.R")
biocLite("clusterProfiler")
#安裝 KEGG.db
biocLite("kegg.db")
#安裝人 org.db 數據庫
biocLite(“org.Hs.eg.db”)
#基因編號轉換
#將基因名稱列表復制給(或者任何你喜歡的文件名),如需分析自己特定的基因集,可替換括號內容,每個基因名稱,用””,隔開。
library(clusterProfiler)
yh <- c("GPX3", "GLRX", "LBP", "CRYAB", "DEFB1", "HCLS1", "SOD2", "HSPA2",
"ORM1", "IGFBP1", "PTHLH", "GPC3", "IGFBP3","TOB1", "MITF", "NDRG1", "NR1H4", "FGFR3", "PVR", "IL6", "PTPRM", "ERBB2", "NID2", "LAMB1", "COMP", "PLS3", "MCAM", "SPP1", "LAMC1", "COL4A2", "COL4A1", "MYOC", "ANXA4", "TFPI2", "CST6", "SLPI", "TIMP2", "CPM", "GGT1", "NNMT", "MAL", "EEF1A2", "HGD", "TCN2", "CDA", "PCCA", "CRYM", "PDXK", "STC1", "WARS", "HMOX1", "FXYD2", "RBP4", "SLC6A12", "KDELR3", "ITM2B")
#利用 cluterProfiler 內置的 bitr 函數進行基因編號轉換,并將轉換后的信息存儲在 gene 文件中
gene <- bitr(yh, fromType="SYMBOL", toType=c("ENTREZID"), OrgDb="org.Hs.eg.db")
head(gene)
##提取 gene 數據中的 ENTREZID 列,并賦值給 DE_list
DE_list <- gene$ENTREZID
#去除重復值
DE_list[duplicated(DE_list)]
integer(0)
#調用 org.Hs.eg.db,并查看文件的各列名稱信息
library(org.Hs.eg.db)
columns(org.Hs.eg.db)
#GO_MF 富集,基于基因數目,如果使用的是個人電腦,配置不高,為防止程序卡死,建議 MF\CC\BP 單個來運行,生成的圖片也逐個生成保存后再運行下一個。
MF <- enrichGO(gene = DE_list, #差異基因 vector
keyType ="ENTREZID",
OrgDb = org.Hs.eg.db, #對應的OrgDb
ont = "MF", #GO 分類名稱,CC BP MF
pAdjustMethod = "BH", #Pvalue 矯正方法
pvalueCutoff = 0.05, #Pvalue 閾值
qvalueCutoff = 0.05, #qvalue 閾值
readable = TRUE) #TRUE 則展示SYMBOL,FALSE 則展示原來的ID
#將 MF 對象轉換為 dataframe,新版本可以用 as.data.frame(MF)
MF_results<-summary(MF)
#生成 barplot PDF 格式,x 軸為 GeneRatio,展示前 20 富集的 GO,數字可以調整
pdf(file = "MF_barplot.pdf")
barplot(MF, showCategory=20, x = "GeneRatio")
dev.off()
#生成 MF 氣泡圖
dotplot(MF)
#GO_CC 富集,基于基因數目
CC <- enrichGO(gene = DE_list, #差異基因 vector
keyType ="ENTREZID",
OrgDb = org.Hs.eg.db, #對應的OrgDb
ont = "CC", #GO 分類名稱,CC BP MF
pAdjustMethod = "BH", #Pvalue 矯正方法
pvalueCutoff = 0.05, #Pvalue 閾值
qvalueCutoff = 0.05, #qvalue 閾值
readable = TRUE) #TRUE 則展示SYMBOL,FALSE 則展示原來的ID
#將 CC 對象轉換為 dataframe,新版本可以用 as.data.frame(CC)
CC_results<-summary(CC)
#生成 barplot PDF 格式,x 軸為 GeneRatio,展示前 20 富集的 GO,數字可調整
pdf(file = "CC_barplot.pdf")
barplot(CC, showCategory=20, x = "GeneRatio")
dev.off()
#生成 CC 氣泡圖
dotplot(CC)
#GO_BP 富集,基于基因數目
BP <- enrichGO(gene = DE_list, #差異基因 vector
keyType ="ENTREZID",
OrgDb = org.Hs.eg.db, #對應的OrgDb
ont = "BP", #GO 分類名稱,CC BP MF
pAdjustMethod = "BH", #Pvalue 矯正方法
pvalueCutoff = 0.05, #Pvalue 閾值
qvalueCutoff = 0.05, #qvalue 閾值
readable = TRUE) #TRUE 則展示SYMBOL,FALSE 則展示原來的ID
#將 BP 對象轉換為 dataframe,新版本可以用 as.data.frame(BP)
BP_results<-summary(BP)
#生成 barplot PDF 格式,x 軸為 GeneRatio,展示前 20 富集的 GO,數字可調整
pdf(file = "BP_barplot.pdf")
barplot(BP, showCategory=20, x = "GeneRatio")
dev.off()
#生成 BP 氣泡圖
dotplot(BP)
#KEGG pathway 富集
ekp <- enrichKEGG(gene = DE_list,
keyType = "kegg",
organism = 'hsa',
pvalueCutoff = 0.05)
ekp_results <- summary(ekp)
#生成 KEGG 富集分析的 barplot 圖,數字可調整
barplot(ekp, showCategory=20, x = "GeneRatio")
#生成氣泡圖
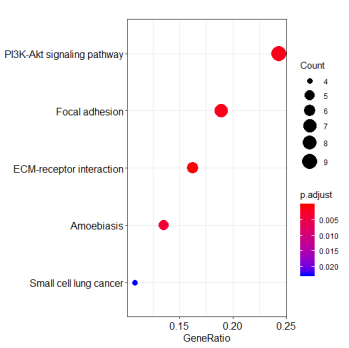
dotplot(ekp)
#基因和富集排名第 1 的pathway對應關系
cnetplot(ekp, showCategory = 1)
#輸出 pathway 富集結果,可以用 excel 打開查看
write.table(ekp, file = "ekp.txt",
sep = "\t", quote = F, row.names = T)
#查看通路
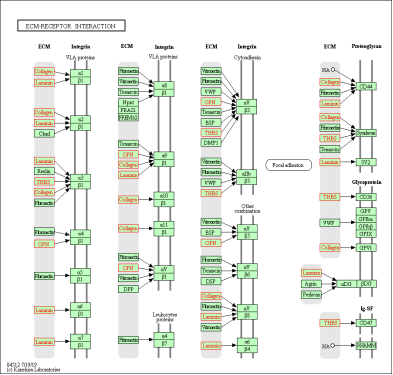
browseKEGG(ekp,'hsa04512')
過程文件展示
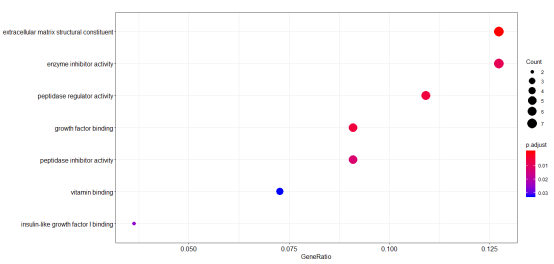
MF_barplot
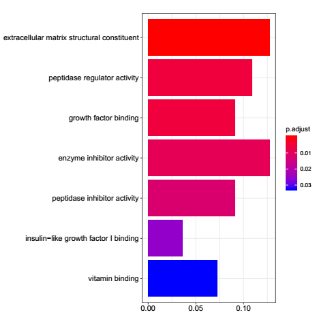
MF_dotplot
KEGG_barplot
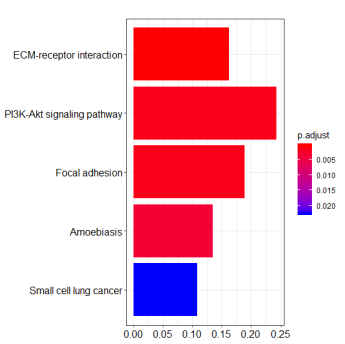
KEGG_dotplot
KEGG enrichment pathway browse
補充說明
#R3.6.0 以上版本安裝方法不同于 R3.5.2 及以下版本,biocManager 安裝方法如下:
If(!requireNamespace(「BiocManager」,quietly=TRUE))
Install.packages(「BiocManager」)
BiocManager::install(「clusterProfiler」,version = 「3.8」)



Copyright(C) 1998-2025 生物器材網 電話:021-64166852;13621656896 E-mail:info@bio-equip.com