基于機器學習的生物過程優化、監測和控制系統綜述
跟蹤智慧實驗室的理論研究發展狀況、產業發展動態、主要設備供應商產品研發動態、國內外智慧實驗室建設成果現狀等信息內容。本文由中科院上海生命科學信息中心與曼森生物合作供稿。
本期“前沿技術”欄目,編譯了 Partha Pratim Mondal 等發表在 Bioresource Technology 期刊上的綜述論文《基于機器學習的生
物過程優化、監測和控制系統綜述》(Review on machine learning-based bioprocess optimization, monitoring, and control systems),作者首先深入介紹了機器學習領域的基本理解,并討論了其復雜性,以獲得更全面的應用。隨后概述了機器學習模型對控制生物過程操作所生成的龐大數據集的統計和邏輯分析的相關性。然后,批判性地討論了生物過程行業不同子領域的當前知識、局限性和未來方面。此外,還討論了采用混合方法將不同的建模策略、網絡和集成傳感器相結合以開發新的
數字生物技術的前景。
目錄/CONTENT
01/前言
02/機器學習的基本概念
2.1 機器學習模型設計
2.2.生物過程開發中的機器學習
2.3.選擇正確的機器學習方法的過程
03/機器學習算法
04/ML 在生物加工工業中的應用
4.1 生物燃料行業
4.2.生物制藥行業
4.3.生物廢水處理
05/研究需求和未來展望
06/結論
1.前言
在生物過程行業中觀察到了這方面的重大發展,新的生物產品和生物工藝的產量成倍增加。這些發展主要與生物加工子領域相關,如生物制藥/生物治療生產、生物燃料生產和生物廢水處理工藝,這些領域的需求從未如此之大。為了確保這些生物產品開發過程的商業經濟性和可持續性, 必須在整個生產生命周期中同步規劃和執行。生物技術行業正在經歷數字化轉型, 以克服這些限制,采用人工智能(AI)和機器學習(ML)等創新技術是相關生產過程自動化的首要任務。基于人工智能的 ML 技術開發、監控、控制和優化過程系統。它們能夠有效地學習工藝參數和性能之間的復雜關系。ML 可以預測和影響關鍵工藝參數(CPP)和產品關鍵質量屬性(CQA),控制工藝系統以應對參數偏差,并理解制造過程中的完整數據分析。
2.機器學習的基本概念
2.1 機器學習模型設計
在 21 世紀末,在開發計算機輔助系統設計、體系結構、計算機視覺和信號處理方面取得了許多進步。ML 被認為是一個研究領域,它允許計算機在最初編程后學習、自學、分析數據和估計,而不需要在每個階段都進行明確的編程。ML 在生物過程行業中已經建立了重要的應用,其影響力展示了領域理解和創新,繞過了人工工作和預測。圖 1a 展示了 ML 在生物過程系統中的使用、相關挑戰、 優勢和模型設計的圖形視圖。圖 1b 描繪了用于生物廢水的機器學習算法的典型圖形工作流程。用于上采樣、下采樣、模型輸入訓練、驗證、測試和機器學習類別(監督、半監督和非監督)的特征點代表了典型的 ML 模型工作流。ML 的領域及其與各種 ML 模型設計和數學方程的關系的綜合視圖見補充表。
因此,為了在自動化設計中處理來自參數數據和圖像的未處理原始文件的挑戰性方面,需要結合起來。深度學習(DL)方法用于此類任務,從而為微流體輔助和高通量生物工藝開發奠定了基礎。DL 領域從未處理的輸入中確定多層次、分層的特征。在同一條線上,深度神經網絡(DNN)由一系列包含激活函數的層組成。使用 I/P-O/P(輸入-輸出)域將多個映射到一個,表示所需的輸出類別,稱為訓練數據。處理測試數據集(看不見的數據)有助于建立和開發相關性模式。ML 與評估中給定數據的統計和經驗模型相互關聯。模型設計的第一部分,即輸入層,確定了原位過程參數、外部生態系統條件和作為 ML 設計和神經網絡模型輸入的幾個觸發神經元(圖 1c)。

2.2.生物過程開發中的機器學習
2.3.選擇正確的機器學習方法的過程
根據任務的性質,ML 規則是明確的,需要一個選擇過程。第一步是選擇 ML 學習的類型,即強化學習、有監督、半監督和無監督的學習方法(見補充材料)。在監督學習中,向算法提供一組“明確的正確答案”或因變量或 y 變量,以拓寬描述自變量和因變量之間關系的特征。變量之間的關系適合進行預測。監督方法為算法提供了最有說服力的統計數據,用于確定數據的一般形式和特征,這是一種實驗策略。為了指示一組規則實現 y 變量目標,ML 包括一個“功績授予功能”, 該功能選擇最大化總體響應的路徑。決定 w-v 比至關重要,其中 w 是輸入的寬范圍,v 是變量的多樣性。更高的 w-v 比率是有益的。然而,真正的成本取決于統計數據和使用情況。例如,如果自變量數據是不可識別的、幾乎沒有噪聲并且高度指示模型試圖遵循的特征,那么大于 5 的低 w-v 比可能就足夠了。相反,如果數據收集量大且有噪聲,則可能需要大于 50 的 w-v 比。建議創建幾個模型, 并使用性能指標進行比較,如絕對誤差、均方誤差、相關系數和預測精度系數。Pearson 系數、p 檢驗、F 評分、混淆矩陣和 Cohenκ 等測試用于確定模型的性能是否優于估計預測。
03 機器學習算法
04ML 在生物加工工業中的應用
ML 算法的使用越來越有規律,以加深對生物過程的理解。該領域的收縮性研究需要將生物化學工程和計算機科學聯系起來。
4.1 生物燃料行業
為了在生物燃料行業取得重大進展,已經進行了廣泛的研究。ML 建模被有意用于研究生物燃料生產中操作參數之間的非線性關系。這一特定研究領域的大量綜述已經發表在公開文獻中。主要集中在 ML 模型在優化、控制和監測生物柴油生產(生物氫、生物乙醇、沼氣等)方面的適應性、靈活性和最新應用。
4.2.生物制藥行業
近年來,原子模擬已成為大型工業中生物制藥過程開發、優化、控制和設計的寶貴工具。ML 技術的制定包括對藥物的可行的普遍需求,以及向具有自動化監管的工業 5.0 的轉變。ML 技術已經在解決生物制藥制造的多個方面找到了基礎。這些研究領域包括生物標志物識別、藥物發現、蛋白質工程、藥物再利用、 臨床試驗質量跟蹤、實時錯誤處理和過程自動化。4.3.生物廢水處理
廢水處理對社區發展至關重要。目前,生物處理工藝是最有效、最可行的工藝。然而,由于生物系統的分支和不確定的時間間隔,生物廢水處理在行業中具有挑戰性。數學建模技術不僅給出了過程動力學的明確描述,而且提前為后續動作提供了提示。因此,必須設計一種有效而明確的廢水處理算法,該算法可以預測瞬態操作條件,如管道泄漏引起的突然故障、生物反應器的操作故障、進料負載的突然變化和不正確的物理參數(即流速、pH 和溫度),以做出現場智能決策。
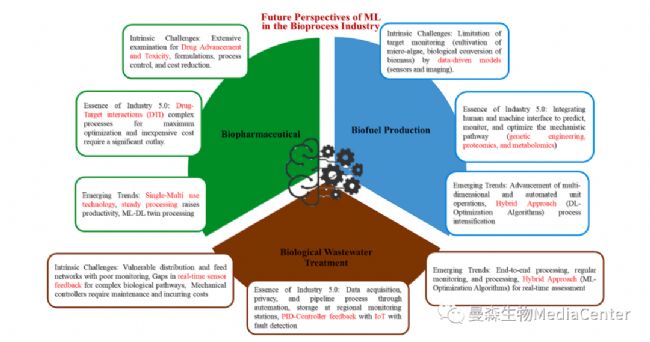
05研究需求和未來展望
盡管在生物過程行業中實現 ML 已經進行了大量的研究和應用,但它仍處于早期開發和使用階段。ML 在企業連續體中的成功應用在很大程度上取決于適當的存儲和數據管理。此外,以下幾點針對生物過程行業中實施 ML 的研究需求和需求:
(1)由于真實的現場數據集的可用性鮮為人知,生物過程中來自軟離線傳感器的反饋增加了不相關和瑣碎信息的成本和交付支出。
(2)利用現場傳感器和算法開發基于網絡的在線物理系統,以控制集成的生物并將其與歷史數據聯系起來。這些成為這種生物過程工業的原始來源投入。即使是生物過程建模系統也不能提供可信的結果。最近的調查表明,運行模擬和統計技術可以優化運營成本,提高運營效率。
(3)基于神經網絡的設計的出現和過程驅動技術的發展,從順序過程到分層再到混合,都在不斷發展。最近,基于模型的控制器被要求通過 ML 進行端到端神經網絡生物過程建模。
(4)單元操作的根本原因分析、分子相互作用和模型細化可以根據傳感器反饋進行多種輸入。這得益于基于混合模型和先進的深度學習架構,如卷積神經網絡-遞歸神經網絡和深度 CNN。這樣的模型在優化和性能指標方面優于競爭對手。
(5)在設計控制技術水平時,必須實現精度、準確性和魯棒性。生物治療開發人員可以從大規模生產的角度進行思考,并從流程開發的早期階段就融入自動化概念。
(6)軟件、硬件和設計規范之間的標準化不足使自動化嘗試變得復雜。
(7)利益相關者和技術解決方案提供商應縮小生物制造領域的創新差距。生物治療開發人員的職責是設計和開發新藥,并建立一個鏈接,提供可以與 ML 集成的自動化解決方案。
(1)需要對生物傳感器進行深入研究,包括微流體傳感器和微型傳感器。高通量表型平臺應使用物聯網和生物燃料和生物制藥行業的混合建模進行連接。
(2)通過 ML 架構設計提供的自動化無線軟傳感器網絡的使用,能夠部署和開發分散的智能產品質量監控系統。
(3)市場上需要一種低成本的無線傳感器節點解決方案來經濟地實現這一 新一代系統。基于物聯網的模塊化設計(圖 2)表明,該系統具有在線和實時管理廢水質量參數的功能。
(5)物聯網集成系統具有先進的功能,可在智能城市的配水系統中部署大規模傳感器,使用戶能夠近實時地識別污染發生和負面趨勢(圖 3 )。

(6)商業或公共機構監測和管理水質的責任將能夠更快、更有效地應對問 題,減少有害影響,減少已發現的問題(即污染點和目標源)。基于 ML 的操作控制的未來使用旨在幫助研究人員和技術人員了解和分析 生物過程屬性、操作周期中的實時參數估計、診斷偏差和分析遇到的錯誤。
文章來源:Mondal PP, Galodha A, Verma VK, et al. Review on machine learning-based bioprocess optimization, monitoring, and control systems. Bioresour Technol. 2023;370:128523. doi:10.1016/j.biortech.2022.128523