Ą░░ū┘|ĮMīWųąĄ─öĄō■¬Ü┴ó▓╔╝»Ż©DIAŻ®öĄō■Ęų╬÷ĘĮĘ©
Ą░░ū┘|ĮMīWųąĄ─öĄō■¬Ü┴ó▓╔╝»Ż©Data-Independent Acquisition, DIAŻ®╩Ūę╗ĘN┘|ūV╝╝ągŻ¼ė├ė┌Ė▀═©┴┐ĪóĖ▀╔ŅČ╚ĄžĘų╬÷Å═ļs╔·╬’śė▒ŠųąĄ─Ą░░ū┘|ĮMĪŻ╦³┼cé„ĮyĄ─öĄō■ę└┘ć▓╔╝»Ż©Data Dependent Acquisition, DDAŻ®ĘĮĘ©ŽÓ▒╚Ż¼╠ß╣®┴╦Ė³╚½├µ║═┐╔ųžÅ═Ą─Ą░░ū┘|ĮMĘų╬÷ĪŻDIA╝╝ągį┌▀MąąĄ░░ū┘|ĮMĘų╬÷ĢrŻ¼▓╗ę└┘ćė┌ŅAŽ╚įOČ©Ą──┐ś╦Ą░░ū┘|╗“ļ─Č╬Ż¼Č°╩ŪŽĄĮyĄžÆ▀├Ķ╦∙ėą┐╔─▄Ą─┘|║╔▒╚(m/z)ĘČć·Ż¼Å─Č°▓Č½@śė▒Šųą▒M┐╔─▄ČÓĄ─Ą░░ū┘|ą┼ŽóĪŻDIAöĄō■Ęų╬÷Ą─║╦ą─▓Į¾E║═╠¶æ░³└©Ż║
1.öĄō■▓╔╝»Ż║
į┌DIA─Ż╩ĮŽ┬Ż¼┘|ūVāxĢ■ŽĄĮyĄžÆ▀├Ķ╦∙ėą┘|┴┐ĘČć·Ż¼Č°▓╗╩ŪāHĘų╬÷ŅAŽ╚▀xČ©Ą─Ū░¾wļxūėŻ©Ž±į┌öĄō■ę└┘ć▓╔╝»DDAųąŻ®ĪŻ
▀@ĘNĘĮĘ©«a╔·Ą─öĄō■░³║¼┴╦śė▒Šųą╦∙ėąļ─Č╬Ą─ą┼ŽóŻ¼Č°▓╗╩Ūų╗ėąūŅžSČ╚Ą─ļ─Č╬ĪŻ
2.ļ─Č╬║═Ą░░ū┘|ĶbČ©Ż║
╩╣ė├īŻķTĄ─▄ø╝■║═╦ŃĘ©╠Ä└ĒDIAöĄō■Ż¼▒╚╚ńSpectronautĪóSkyline╗“MaxQuantŻ¼ęįūRäe║═Č©┴┐ļ─Č╬║═Ą░░ū┘|ĪŻ
▀@═©│Ż╔µ╝░┼cĄ░░ū┘|╗“ļ─Č╬öĄō■ÄņĄ─Ųź┼õŻ¼ęį╝░╩╣ė├Å═ļsĄ─ą┼╠¢╠Ä└Ē╝╝ągĪŻ
3.öĄō■╚źįļ║═╠Ä└ĒŻ║
DIAöĄō■ę“ŲõĖ▀Å═ļsČ╚Ż¼ąĶę¬ėąą¦Ą─╚źįļ║═öĄō■╠Ä└Ē▓▀┬įŻ¼ęį╠ß╚ĪėąęŌ┴xĄ─╔·╬’ą┼ŽóĪŻ
░³└©ą┼╠¢ÅŖČ╚Ą─ąŻ£╩ĪóĘÕūRäeĪóī”²Ręį╝░Č©┴┐Ęų╬÷ĪŻ
4.╔·╬’ą┼ŽóīWĘų╬÷Ż║
Ęų╬÷╦∙ĶbČ©║═Č©┴┐Ą─Ą░░ū┘|║═ļ─Č╬Ż¼ęįĮę╩Š╔·╬’īW▀^│╠Īó▓Ī└ĒÖCųŲ╗“╝▓▓Īś╦ųŠ╬’ĪŻ
░³└©╣”─▄ūóßīĪó═©┬ĘĘų╬÷ĪóĄ░░ū┘|ŽÓ╗źū„ė├ŠWĮjĄ─śŗĮ©Ą╚ĪŻ
5.ĮyėŗĘų╬÷Ż║
▀MąąĮyėŗĘų╬÷ęį┤_Č©Ą░░ū┘|▒Ē▀_Ą─’@ų°ūā╗»Ż¼▀@ī”ė┌╝▓▓Ī蹊┐║═╔·╬’ś╦ųŠ╬’Ą─ĶbČ©ė╚×ķųžę¬ĪŻ
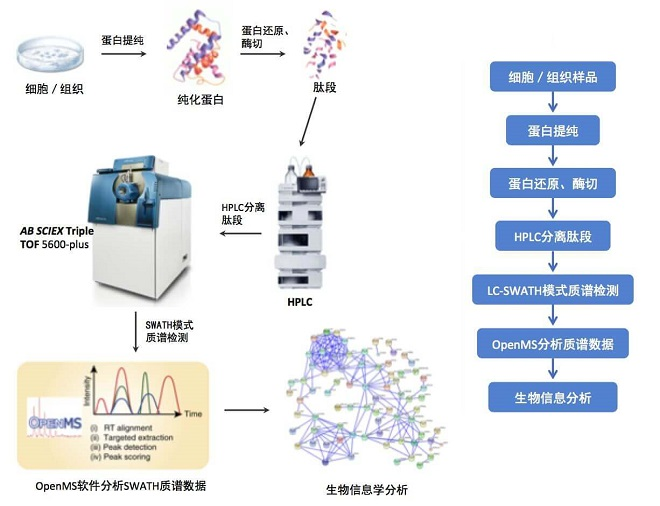
łD1.DIAČ©┴┐Ą░░ū┘|ĮMīW
DIA╝╝ągį┌Ą░░ū┘|ĮMīWųą╠ß╣®┴╦ę╗ĘNÅŖ┤¾Ą─╣żŠ▀Ż¼╦³į╩įSī”śėŲĘ▀MąąĖ³╚½├µ║═╔Ņ╚ļĄ─Ęų╬÷Ż¼Ą½═¼Ģrę▓ąĶę¬Ė▀╝ēĄ─Ęų╬÷ĘĮĘ©║═╦ŃĘ©üĒ╠Ä└Ē║═ĮŌßīöĄō■ĪŻ

- ęĒ║═╔·╬’SNP╗∙ę“Ęųą═╝╝ągŻ║Įę├ž╗∙ę“├▄┤aŻ¼╠ĮīżīÜīÜĮĪ┐Ąų«┬Ę
- ┤┘─I╔ŽŽ┘Ųż┘|╝ż╦žßīĘ┼╝ż╦žŻ©CRHŻ®į┌╠Į╦„Ę╩┼ųÖCųŲųąĄ─蹊┐
- ├┌─“ŽĄĮy╝▓▓ĪĄ─ĻPµIų╬»¤░ą³cų«V2RĄ─ĮķĮB╝░ŽÓĻPīŹ“×
- ╝ż╣Ō╣▓Š█Į╣’@╬óńRų·┴”─[┴÷ęųųŲä®čąŠ┐
- ┐šķgČÓĮMīWĮŌ┤a─[┴÷╬óŁhŠ│Ż¼ų·┴”╝ė╦┘Š½£╩ų╬»¤čąŠ┐
- └¹ė├å╬╝Ü░¹▐DõøĮM╝╝ągĮŌ╬÷ČÓĘN├Ōę▀╝Ü░¹ī”┤¾┴┐╝Ü░¹ę“ūėĄ─Ēææ¬
- EmulateŲ„╣┘ąŠŲ¼ų·┴”蹊┐╦Ä╬’ę²ŲĖ╬ōpé¹Ą─ÖCųŲ
- ╣Ū┘|╩Ķ╦╔║═╝ūĀŅ┼įŽ┘╣”─▄£p═╦ĻPµI░ą³cPTH1RĄ─ĮYśŗ╣”─▄╝░ŽÓĻPīŹ“×ĮķĮB
- ╔·╬’ąŠŲ¼═Ų│÷"ąŠ┐šę╗╠¢"ĘĮ░Ėųž╦▄┐šķgČÓĮMīWą┬ĘČ╩Į
- IPHASEšn╠├ķ_šn└▓Ż║╝ÜŠ·╗žÅ══╗ūāįć“×│ŻęŖå¢Ņ}┼cĮŌ┤
- ╔·╬’ąŠŲ¼┼cąŠ│¼╔·╬’┬ō║Ž═Ų│÷"ąŠ┐šę╗╠¢"ČÓĮMīWĘĮ░Ė
- ╔·╬’ßt╦ÄÖz£y┼cįćä®╣®æ¬╔╠ęĒ║═╔·╬’Ž“╚½ć°šą─╝ĮøõN╔╠
- ŠĆ╔Žšn│╠Ż║ži─cĄ└╣┌ĀŅ▓ĪČŠ┼c╚╦¾w¤o┬ĢĄ─┤·ųxČĘĀÄ
- ę╗ū„ų▒▓źŻ║┐╣ąįĄĒĘ█═©▀^ųž╦▄─cĄ└╬ó╔·╬’╚║ŠÅĮŌĘ╩┼ų
- SBC&─Ż╗∙╔·╬’2024─ĻĄ┌ę╗Ų┌ŅÉŲ„╣┘│§╝ē┼Óė¢░Óč¹šł║»
- SBCč¹─·ģó╝ė2024┐šķgČÓŠSĮMīWäōą┬▐D╗»čąėæĢ■