蛋白質組學差異蛋白篩選的數據處理方法
蛋白質組學作為研究蛋白質組成、結構和功能的學科,已成為生物醫學研究中的重要領域。蛋白質組學的差異蛋白篩選是其中的關鍵步驟,旨在發現在不同條件下表達量發生變化的蛋白質,并探究其對生物學過程的影響。然而,面對大規模的蛋白質組學數據,如何進行數據處理成為了一個重要的挑戰。本文將詳細介紹蛋白質組學差異蛋白篩選的數據處理方法,幫助讀者更好地理解如何從大規模數據中發現生物學意義。
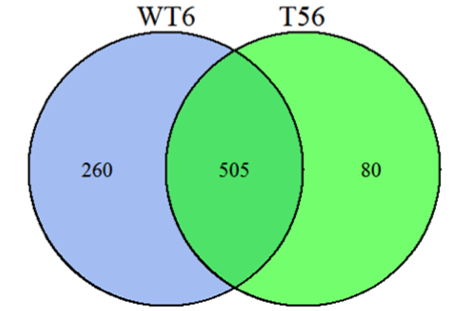
圖1
1、蛋白質組學差異蛋白篩選的數據處理流程
蛋白質組學差異蛋白篩選的數據處理流程包括數據預處理、差異分析和生物學解釋三個主要步驟。
1.1 數據預處理
數據預處理是數據分析的第一步,用于去除實驗中的技術變異和非生物學變異。常用的數據預處理方法包括峰識別、峰定量和數據歸一化等。
1.2 差異分析
差異分析旨在識別在不同樣本組之間具有顯著差異的蛋白質。統計學方法如t檢驗、方差分析、假設檢驗等常被應用于差異分析。此外,還可采用多元分析和機器學習等方法進行更全面的差異分析。
1.3 生物學解釋
生物學解釋是將差異蛋白與生物學過程和疾病相關聯的關鍵步驟。通過生物信息學數據庫的查詢和功能富集分析,可以了解差異蛋白所參與的信號通路、生物過程和分子功能,從而推斷其在生物學中的作用。
2、常用的蛋白質組學差異蛋白篩選數據處理方法
2.1 差異蛋白鑒定
差異蛋白鑒定是蛋白質組學中的關鍵任務之一。常用的差異蛋白鑒定方法包括基于質譜數據的標準比對、蛋白質鑒定搜庫和非標記定量方法等。
2.2 生物信息學分析
生物信息學分析是蛋白質組學數據處理中的重要環節。它通過對差異蛋白進行功能富集分析、互作網絡分析和通路分析,揭示差異蛋白在生物學過程中的潛在作用和相互關系。
3、蛋白質組學差異蛋白篩選的生物學意義
蛋白質組學差異蛋白篩選的數據處理方法不僅能夠幫助鑒定和定量差異蛋白,還能揭示蛋白質在生物學過程和疾病發展中的重要作用。通過對差異蛋白的生物學解釋,我們可以深入了解蛋白質參與的信號通路、調節網絡和生物過程,為生物醫學研究和藥物開發提供重要的線索。
蛋白質組學差異蛋白篩選的數據處理是蛋白質組學研究中至關重要的一環。通過合理選擇和應用數據處理方法,我們能夠從大規模的蛋白質組學數據中發現生物學意義,揭示蛋白質在生物學過程和疾病發展中的重要作用。未來,隨著技術的不斷發展,蛋白質組學數據處理方法的改進將進一步推動生物醫學研究的進展。