技術解析:CytScop®智能細胞計數(shù)儀AI模型的構建過程分析
構建細胞計數(shù)AI模型的關鍵步驟
1、多模態(tài)數(shù)據(jù)集采集與標注
構建多模態(tài)生物醫(yī)學圖像數(shù)據(jù)集,集成明場/熒光/無標記成像技術,覆蓋貼壁細胞、懸浮細胞等不同細胞類型及藥物處理、分化階段等多樣化實驗條件。通過旋轉、縮放、翻轉等數(shù)據(jù)增強策略擴充樣本多樣性,提升模型泛化能力。建立標準化標注體系,針對目標檢測任務實施邊界框標注(適配Faster R-CNN等檢測模型),圖像分割采用像素級標注(支撐U-Net等分割網(wǎng)絡),實例分割則通過區(qū)分重疊細胞實現(xiàn)(凸顯Mask R-CNN技術優(yōu)勢)。
2、數(shù)據(jù)預處理技術
采用多維度圖像增強手段提升模型魯棒性,包括幾何變換(旋轉/縮放/翻轉)和噪聲模擬等操作。實施標準化處理流程,統(tǒng)一調節(jié)圖像亮度、對比度參數(shù),運用中值濾波等降噪方法消除背景干擾,確保輸入數(shù)據(jù)的規(guī)范性和一致性。
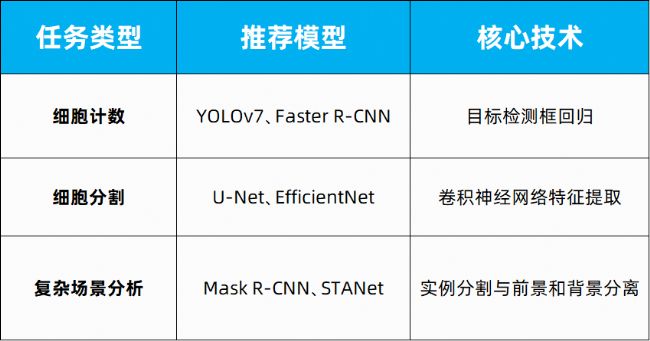
3、核心算法與模型選擇
基于具體任務需求選擇適宜的深度學習架構,針對細胞計數(shù)場景可能涉及目標檢測(如YOLO系列)、圖像分割(如U-Net變體)等核心技術路線,結合遷移學習策略優(yōu)化模型適應性。
4、模型訓練
配置損失函數(shù)(分類任務采用交叉熵損失,回歸任務使用均方誤差,分割任務應用Dice系數(shù)),選用Adam/SGD等優(yōu)化器并精細調整學習率、動量等超參數(shù)。通過反向傳播算法迭代優(yōu)化網(wǎng)絡權重,利用訓練集完成模型參數(shù)訓練過程。
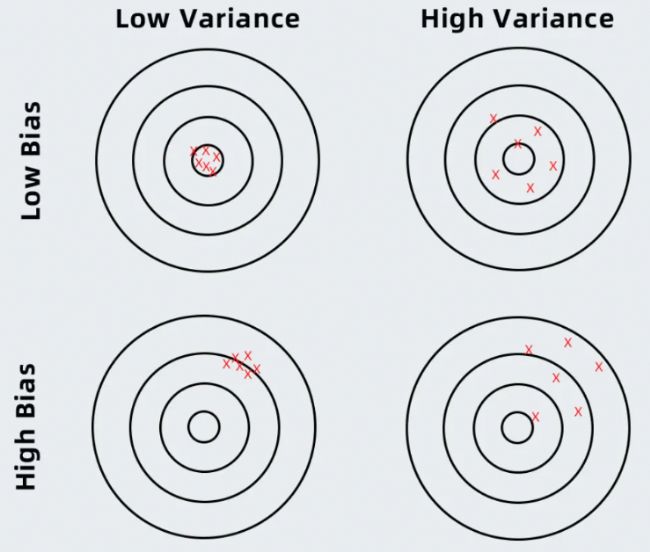
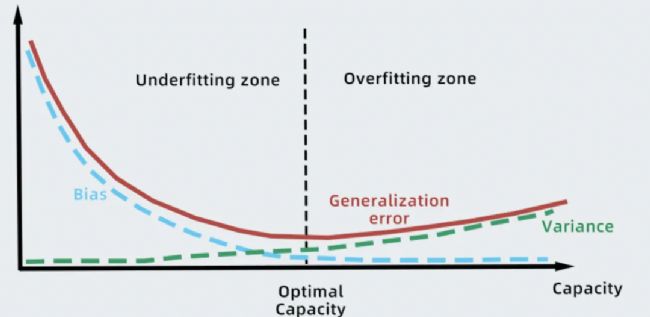
5、模型驗證與調優(yōu)
搭建獨立驗證集防止過擬合,采用網(wǎng)格搜索/隨機搜索進行超參數(shù)優(yōu)化,動態(tài)調整學習率、批量大小等關鍵參數(shù)。結合遷移學習策略持續(xù)優(yōu)化數(shù)據(jù)增強方案,通過多輪驗證提升模型泛化性能。
6、模型評估
建立多維度評估體系,計算準確率、召回率、F1分數(shù)等分類指標,采用交并比(IoU)量化分割精度。通過混淆矩陣分析類別識別偏差,借助熱力圖、邊界框可視化工具直觀呈現(xiàn)預測結果分布特征。
7、模型部署與持續(xù)迭代
運用模型剪枝、量化壓縮等技術降低計算負載,優(yōu)化推理速度。將訓練成果集成至自動化細胞計數(shù)工作流,構建實時處理系統(tǒng),支持高吞吐量的臨床樣本分析需求。同時,建立數(shù)據(jù)迭代機制,持續(xù)采集模型薄弱場景的新樣本。制定周期性模型更新策略,通過增量訓練保持模型性能適應性,確保系統(tǒng)長期穩(wěn)定運行。
CytScop®細胞計數(shù)的AI模型
CytScop®的AI模型是基于卷積神經(jīng)網(wǎng)絡CNN的模型架構的深度學習方法;訓練后的模型在本地CPU上運行時,單次運算小于1秒;不再需要人為設置各種參數(shù)閾值如直徑、亮度、圓度、系數(shù)等,對不同的細胞類型/生物工藝具有良好的可拓展性與更準確的泛化能力。


AI模型憑借其高效、準確、適應性強等優(yōu)勢,徹底改變了細胞計數(shù)的方式,為生物制藥的智能化發(fā)展帶來了新的機遇和突破。隨著AI技術的不斷發(fā)展和完善,其在細胞計數(shù)領域的應用前景將更加廣闊,推動整個生命科學領域邁向新的高度。