基于 AI 的篩選技術在藥物研發領域的應用
2024 年 9 月 9 日,首屆上海國際計算生物學創新大賽•藥物篩選 AI 算法“凌越”挑戰賽正式落下帷幕。86 支來自國內外的頂尖計算生物參賽團隊運用人工智能 (AI) 算法,在這場智慧與實力的比拼中各顯神通。
MCE 中國作為大賽的獨家協辦方,為大賽提供包含 1800 萬個化合物的數據資源以及約 1000 個實體化合物分子。
經過高通量測試,上海藥物所發現 223 個分子具有活性,并經過多輪測試,最終選出 5 個最具有特異性的潛力分子。伴隨著“藥篩+AI”的強強聯手,賽事不僅展示了前沿科技的應用,也彰顯了AI在藥物研發過程中的巨大潛力和重要價值。
01
基于 AI 的篩選技術,有哪些優勢?
眾所周知,傳統的藥物發現之旅是艱難的,大多數的藥物需要 10-15 年才能進入臨床,花費數百萬甚至數十億美元的成本,最終,大多數候選藥物會由于安全或者療效問題而失敗。
隨著 AI 時代的到來,越來越多的事實證明,AI 是藥物發現過程中的強大工具,為長期存在的挑戰提供了創新的解決方案。
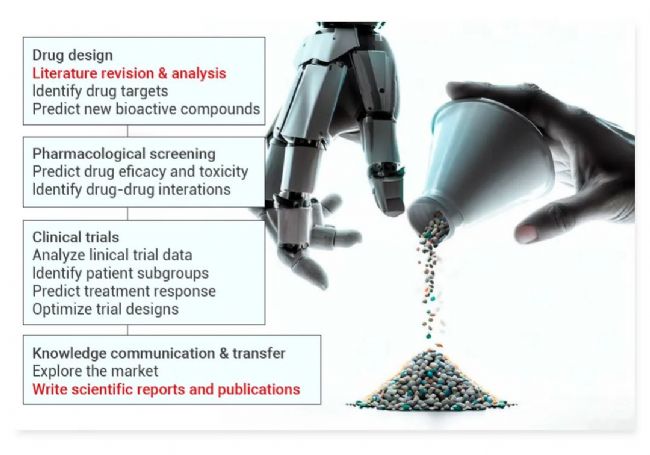
圖 1. 藥理活性分子從設計到知識交流和傳遞的開發過程[1]。
基于 AI 篩選的優勢:
1. AI 算法可以篩選龐大的生物數據庫,以前所未有的速度和高精度識別潛在的藥物靶點。
2. 通過分析從基因組到臨床的所有數據,AI 工具可以精確定位在疾病進展中起關鍵作用的分子和生物途經,為研究人員提供關于潛在治療干預措施的寶貴見解。
3. 同時基于 AI 篩選技術對大型的化合物庫數據進行快速的篩選,以識別最有可能與靶標結合的化合物,這個過程曾經耗時且成本高昂,現在可以在短時間內完成,大大加快了藥物發現的步伐。
4. 此外,AI 驅動的預測模型可以幫助研究人員更準確的評估候選藥物的有效性和安全性,從而指導優先對哪些化合物進行進一步的優化和測試。
02
基于 AI 的藥物發現,如何應用?
AI 輔助藥物研發成功案例
AI 在藥物發現中的潛力已經在很多案例中得到證明。例如,Gupta,R. 等人 2021 年報道了基于已知癌癥相關化合物和相應的生物活性的大型數據集訓練了 DL (深度學習) 算法,結果獲得了具有癌癥治療潛力的新型化合物,證明了 AI 在發現新型候選藥物的能力[2]。
MEK 也是治療癌癥的潛在靶點,但是該靶點的有效抑制劑的開發一直具有挑戰性,Zhu,J 等人在 2021 年報道了通過訓練 ML (機器學習) 算法,識別出這種蛋白質的新型抑制劑[3]。另一個例子是通過使用 ML 算法發現 β-分泌酶 (BACE1) 的新型抑制劑,BACE1 是一種參與阿爾茲海默癥的蛋白[4]。在 COVID-19 大流行期間,AI 的潛力顯得尤為突出,AI 算法被用于分析潛在的大型化合物數據集,并確定了最有可能對抗該病毒的化合物[5][6][7][8][9][10]。
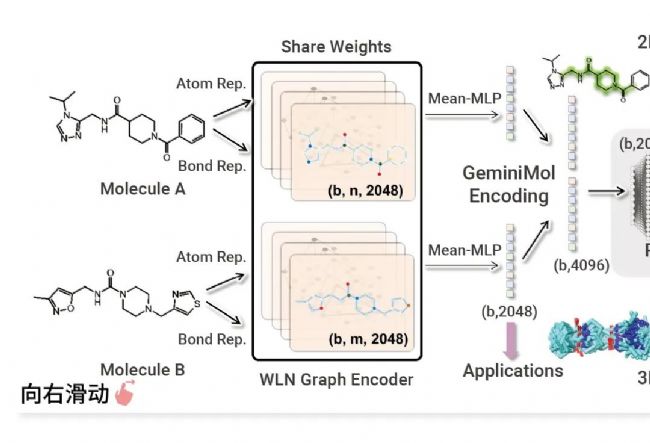
本次 AI 大賽獲得一等獎的團隊為上科大的 GeminiMol 團隊,構象空間是他們的一大亮點,該模型能夠識別 2D 結構不相似,但 3D 構象相似的潛在活性分子,有助于發現具有新穎結構的先導化合物。該模型基于分子間構象空間相似性對比學習來進行訓練,能夠表征藥物小分子的構象空間特征,全面反映與分子結構相關的分子屬性、潛在藥效性質等,進而在包括基于配體的虛擬篩選、靶標鑒定、分子屬性預測等多種藥物發現任務上表現出均衡的優良性能。
近日,該模型相關論文“Conformational Space Profiling Enhances Generic Molecular Representation for AI-powered Ligand-based Drug Discovery”已發布于國際期刊 Advanced Science 雜志。

AI 制藥,未來會怎么樣?
去年,Insilico Medicine 公司基于 AI 生成的抗纖維化藥物,名為 INS018_055,是首個進入臨床II期實驗的化合物。
今年 3 月,Insilico 在 Nature Biotechnology 上詳細報道了從采用大型語言模型 (LLM) 生成到臨床試驗的整個過程。
2023 年,美國食品和藥品管理局 (FDA) 發布了 AI 在藥物發現中使用的相關指南,該報告強調了潛在的關鍵應用領域,同時也考慮到了降低風險以及對這一技術更明確的指導方針。在更清晰的指導下,研究人員能夠更好的應用這項技術。
另一個確保 AI 最佳實踐的條件是建立對模型的信任,在最近的 Front Line Genomics 網絡研討會上,Richard Lewis (Novartis 計算機輔助藥物設計數據科學總監) 討論了模型構建的社會學考慮因素以及 AI 在藥物發現中的地位。如果研究人員對這項技術有更好的理解和信任,那么 AI 應該能夠在此過程中更有效地使用。
盡管截止 2024 年,尚未有 AI 生成的藥物獲批上市,科學家仍在努力推動AI在藥物發現中的應用。
04
MCE:一站式藥篩平臺
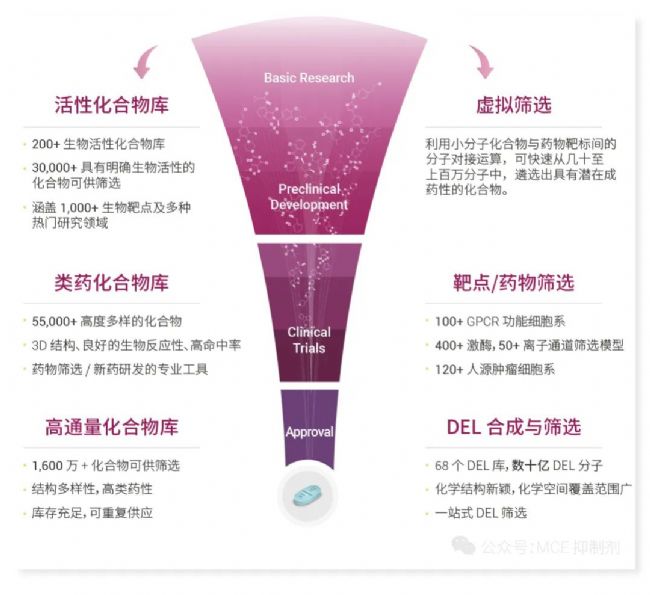
MCE 一站式藥篩平臺聚焦于藥物發現早期,積極擁抱 AI 帶來的巨大機遇和挑戰,將越來越多的 AI 技術應用到各個業務模塊。化合物庫方面,除了通過 AI 算法生成 MegaUni 1,000 萬虛擬類藥多樣庫,還將 AI 算法應用到各種類型的 Mini 化合物庫的構建,幫助客戶更高效地獲得符合自己需求的化合物庫。虛擬篩選方面,將 AI 主動學習和分子對接相結合,以支持更大規模的虛擬篩選。
此外,MCE 擁有已知活性庫、類藥多樣庫、特色片段庫及藥物篩選、先導化合物優化技術平臺為全球科研客戶及新藥研發客戶提供—站式藥物發現及研究服務。
未來,平臺將緊跟全球研發前沿,持續豐富專業資源與科研工具,提升視覺形象與用戶體驗,鏈接全球產業鏈資源,推進產業提質增效。在系統化、專業化、精益化的戰略引領下,平臺致力于打造適合科學研究領域的一站式藥物發現及研究服務平臺,構建開放、公益的化合物信息共享平臺,為科學研究提供各種化合物與試劑,為科研工作者和學術界提供一個創新、高效、協作的平臺,為新藥研發提供智能化解決方案,更好推動科學發展和知識共享。
|
產品推薦 |
|
DNA 編碼化合物庫(DNA Encoded compound Library,DEL)技術作為新穎、強大的苗頭化合物發現引擎,可快速從幾千萬至數十億分子中,遴選出結構新穎、具有潛在成藥性的化合物,大大縮短藥物研究周期,降低研發成本。在 DEL 庫中,每一個分子砌塊(Building Block)都由一段已知唯一的 DNA 序列進行標記,通過 DNA 兼容反應和組合化學模式,歷經數個循環即可獲得上億 DEL 分子。數十億化合物可以混合在一管中篩選,最終通過高通量測序技術,解碼 DEL 分子的專屬 DNA 標簽,快速獲得針對靶點的苗頭化合物信息。 |
|
50K Diversity Library (HY-L901) 由 50,000 種類藥化合物組成。本多樣性庫具備新穎性、類藥性,結構多樣性等特點,庫中化合物可重復供應,是新藥研發的有力工具,可以廣泛地應用于高通量篩選 (HTS) 和高內涵篩選 (HCS)。 |
|
5K Scaffold Library(HY-L902) 由 5,000 種類藥化合物組成,每種化合物代表一種結構骨架,最大程度保證了庫的結構多樣性。庫中的化合物均經過 MedChem & PAINS filters 篩選,剔除了不合適的化學結構,避免“目標錯誤”。本庫化合物數量少但結構足夠多樣,是藥物篩選的有力工具。 |
|
3D Diverse Fragment Library (HY-L903) 由 5,196 個非平面片段分子組成 (平均 Fsp3 值為 0.58),超過 4,700 個片段至少包含一個手性中心。本庫設計的關鍵元素是 3D 結構、多樣性、生物反應性等,有效提高了片段潛在生物活性,為基于片段的藥物發現提供了更高的片段命中概率。 |
|
Drug Fragment Library (HY-L904) MCE Drug Fragment Library 由 1,000 個藥物片段組成。這些藥物片段來自 2,946 個 FDA 已批準的藥物分子,同一藥物的不同片段可以出現在其他藥物中,這些片段和 PK/PD 性質存在一定的相關性,基于片段的篩選可以為后續優化結構預留出足夠的化學空間,該化合物庫是 FBDD(基于片段的藥物設計)藥物篩選的必備工具。 |
|
Natural Product-like Library (HY-L905) MCE Natural Product-like Compound Library 由 5,000 個來自類藥庫的類天然產物化合物組成,庫中每個分子含有天然產物關鍵骨架(42 個)或者和天然產物的谷本相似系數大于 0.6,且Natural-likeness scoring > -2,該化合物庫同時具備類藥性和新穎性,庫中化合物可重復供應,是新藥研發的有力工具,可以廣泛地應用于高通量篩選 (HTS) 和高內涵篩選 (HCS)。 |
參考文獻:
[1] Blanco-González, et al. The Role of AI in Drug Discovery: Challenges, Opportunities, and Strategies. Pharmaceuticals 2023, 16,891.
[2] Gupta, R.; et al. Artificial intelligence to deep learning: Machine intelligence approach for drug discovery. Mol. Divers. 2021, 25, 1315–1360.
[3] Zhu, J.; et al. Prediction of drug efficacy from transcriptional profiles with deep learning. Nat. Biotechnol. 2021, 39, 1444–1452.
[4] Dhamodharan, G.; et al. Machine learning models for predicting the activity of AChE and BACE1 dual inhibitors for the treatment of Alzheimer’s disease. Mol. Divers. 2022, 26, 1501–1517.
[5] Lv, H.; et al. Application of artificial intelligenceand machine learning for COVID-19 drug discovery and vaccine design. Brief. Bioinform. 2021, 22, bbab320.
[6] Monteleone, S.; et al. Fighting COVID-19 with Artificial Intelligence. In Methods in Molecular Biology; Humana Press Inc.: Totowa, NJ, USA, 2022; Volume 2390, pp. 103–112.
[7] Zhou, Y.; et al. Artificial intelligence in COVID-19 drug repurposing. Lancet Digit. Health 2020, 2, e667–e676.
[8] Verma, N.; et al. Predicting potential SARS-CoV-2 drugs-in depth drug database screening using deep neural network framework ssnet, classical virtual screening and docking. Int. J. Mol. Sci. 2021, 22, 1392.
[9] Bung, N.; et al. De novo design of new chemical entities for SARS-CoV-2 using artificial intelligence.Future Med. Chem. 2021, 13, 575–585.
[10] Floresta, G.; et al. Artificial Intelligence Technologies for COVID-19 De Novo Drug Design. Int. J. Mol. Sci. 2022, 23, 3261.
[11] Wang L, et al. Conformational Space Profiling Enhances Generic Molecular Representation for AI-Powered Ligand-Based Drug Discovery. Adv Sci (Weinh). 2024 Aug 29:e2403998.