定量蛋白組學技術概覽
定量蛋白質譜作為蛋白組學檢測中非常重要的檢測手段,主要可以分為無標記定量蛋白組學(label free)、標記定量蛋白組學(TMT/iTRAQ),而無標記定量中根據質譜數據采集方式的差異也可以分為DDA(數據依賴性采集)和DIA(數據非依賴性采集)兩種方式,今天我們詳細了解一下這些技術的特點和區別。

圖1 定量蛋白組學分類
常規的非標記定量蛋白組學方式檢測一般是每個樣本分別先后上機檢測,而質譜作為一個高度精密的儀器,其特點是容易受到外界環境等因素的干擾,進而導致不同批次樣本甚至同一批次先后測量的樣本之間存在客觀系統性偏差,進而影響我們實驗結果的可靠性。而標記定量蛋白組學的出現,通過對不同樣本進行同位素標簽標記,進而可以混合多個樣本為一個樣本進行同時檢測,避免了檢測批次、先后的問題,而且通過樣本的混合,減少了樣本上機數量,可以通過增加單個檢測時間提高對于混合后樣本的檢測深度,最終達到檢測平行性更好,檢測到的蛋白數量更多的目的。
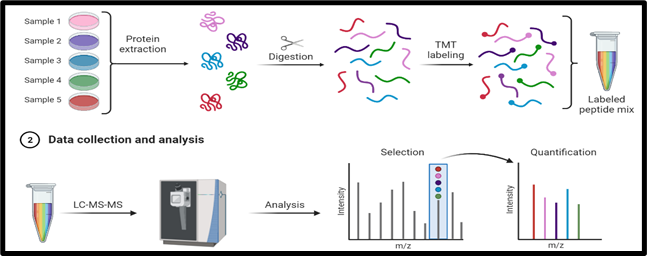
圖2 標記定量流式示意圖
當然常規的label free非標記定量方法并非一無是處,其優勢為無需標記(減少對樣本處理)成本較低,沒有樣本數量限制(標記法的同位素標簽數量有限),且樣本損耗較少,需求的起始樣本量較少,對于一些珍貴的而且蛋白復雜度相對較低的樣本比如外泌體等尤其合適,一般同批次內的檢測穩定性也是足夠的。
非標記定量蛋白組學中傳統使用的DDA數據采集模式,意味著質譜檢測時一級質譜上只能選擇峰排名較高的前多少名質譜峰離子進行二級質譜鑒定(定性),導致很多低豐度蛋白的丟失和樣本間平行性變差(每次檢測有一些概率性存在);所以目前大樣本量檢測時也有使用DIA(數據非依賴性采集)方法,該方法通過質譜的多個窗口循環檢測不同分子量區間的所有肽段,這樣避免了一些低含量肽段的丟失,提高了檢測的穩定性。

圖3 DDA采集模式_VS_ DIA數據采集模式
DIA數據采集模式尤其優勢,然后也有存在一些亟需解決的一些問題,由于其數據采集方式,其二級質譜的復雜度極高,所以早期對于其DIA質譜譜圖的解析存在一定的困難,都是需要專門先通過DDA模式建立一個譜圖庫后,在這個基礎上再通過DIA檢測數據去匹配DDA的譜圖來解譜鑒定,這就導致了成本的上升以及建庫過程仍舊使用DDA模式的弊端,所以目前越來越多的軟件和算法在進行開發,可以基于機器學習等算法可以實現直接對DIA數據進行分析,為后續DIA發展奠定良好的基礎。
定量蛋白組學目前技術多種多樣,一般來說每種技術存在都有其合理性,根據自身實際的樣本情況,實際實驗目等的選擇最適合自己的技術方法即可,不必盲目的追求高通量和高深度等技術指標,最后總結了一下各個技術的對比優缺點表格如下:

表1 定量蛋白組學對比
華盈生物專注于蛋白組學研究,以讓蛋白組學研究更簡單為使命,深耕蛋白組學多年,有著深厚的蛋白組學檢測和分析經驗,歡迎廣大老師咨詢和交流。